StableVITON 모델에 대해서 아시나요?
StableVITON 은 가상 피팅 모델 VITON(Virtual Try-On Network)에서 발전한 이미지 생성 모델로 Input으로 의류 이미지와 인물 이미지를 입력하면 인물이 입력한 옷을 입은 Output 이미지를 생성해줍니다.
https://arxiv.org/abs/2312.01725
StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
Given a clothing image and a person image, an image-based virtual try-on aims to generate a customized image that appears natural and accurately reflects the characteristics of the clothing image. In this work, we aim to expand the applicability of the pre
arxiv.org
이번 포스팅은 관심을 두고 봤던 StableVTION을 간략하게 요약해봤습니다!
1. Abstract
StableVITON 모델은 기존 VITON 모델에서 아쉬웠던 의류의 세부사항 보존을 목표로 합니다. 기존에 사전 학습된 모델의 강력한 생성 능력을 효과적으로 활용하며, 의류의 세부사항을 보존하기 위해서 Zero Cross-Attention Blocks 과 Attention Total Variation Loss를 제안합니다.
1. Zero Cross-Attention Block
- 의류와 인체의 대응 학습에서 의류의 디테일을 보존합니다.
- 옷을 인체의 형태에 맞추는 Warping 과정에서 사전 학습된 모델을 활용하여 고품질 이미지를 생성합니다.
2. Attention Total Variation Loss
- 기존의 Cross-Attention 레이어는 의류를 인체에 성공적으로 매핑하지만, Attention 점수값이 높은 지점들이 한 곳에 모이지 않고 분산된 위치에 나타나는 문제가 있습니다.
- Attention Total Variation Loss으로 더 정확한 매핑 값을 생성해 세부사항을 정확히 표현합니다.
2. Model Architecture

데이터 입력
U-Net (SD Encoder)에 다음 4개의 데이터를 입력합니다
- 기존 이미지의 noise 를 적용한 이미지
- 의류 부분을 회색으로 처리한 agnostic 이미지
- agnostic 이미지의 색상 대비를 적용한 agnostic_mask 이미지
- 인체의 포즈 보존을 위한 densepose 이미지
CLIP Encoder 에는 의류 이미지를 입력합니다.
Spatial Encoder (train의 가중치를 복사한 인코더) 에도 의류 이미지를 입력합니다.
Zero Cross Attention
기존 U-Net 구조에서는 정렬되지 않은 의류 map을 인체 map에 더하기만 했습니다.
이는 의류와 인체 간의 불일치(Misalignment)로 인해 의류 세부사항을 보존하지 못했기에 StableVITON 은 다음과 같은 방법을 사용합니다.
- SD Decoder Block에서 Self-Attention으로 의류와 인체의 가중치 학습 후, Cross-Attention으로 Query 전달
- Spatial Encoder에서 Key 와 Valeu 값을 가져와 1에서 전달된 Query 와 병합
- misalignment 와 같은 유해한 노이즈를 제거하기 위해, feed-forward 작업 후, 초기 가중치가 0인 Zero Linear Layer로 추출
* 왜 Spatial Encoder에서 Key 와 Valeu 값을 가져와 Query와 병합하는가 ? *
크로스 어텐션을 통해 의류를 인체의 정확한 부위에 매핑하려면, Key(의류)와 Query(인체) 간의 대응이 이루어져야 합니다.
예를 들어, 오른쪽 어깨 Query가 있을 때, 의류의 오른쪽 어깨 Key가 높은 Attention 점수를 보여야 합니다.
Zero Cross Attention Block을 추가했음에도 아래 그림의 (a)와 같이 정확한 매핑이 이루어지지 않았습니다.

따라서, Attention Total Variation Loss를 추가합니다.
Attention Total Variation Loss
Attention 점수가 높은 지점들이 분산된 위치에 나타나서 생성된 이미지에서 색상 불일치(위 그림의 (b))와 같은 세부사항의 부정확성을 유발합니다. 이를 해결하고자 Attention 맵을 평균화하고 2D로 정규화된 Grid를 가중합으로 계산한 Attention Total Variation Loss를 구합니다.
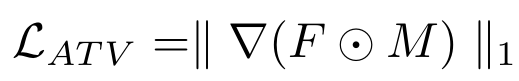
Attention Total Variation Loss는
1. 중심 좌표가 Attention 맵에서 균등하게 분포되도록 강제하며,
2. 분산된 위치에서 발생하는 Attention 점수의 간섭을 완화합니다.
결과적으로, 위 그림의 (c)와 같은 더 정밀화된 어텐션 맵이 생성되어 의류의 색상을 더 정확하게 반영합니다.
3. Evaluation
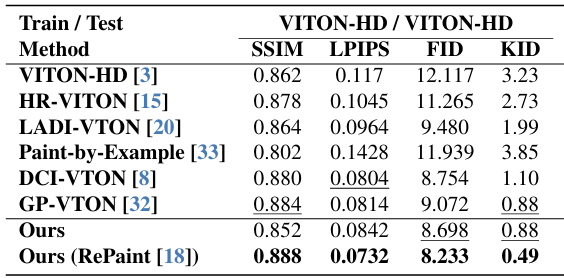
StableVITON 은 VITON 의 시초 모델 격인 VITON-HD 와 GAN 기반 모델인 GP-VTON 까지 총 6개의 모델보다 우수한 성능을 보였습니다. 특히, KID 지표에서 월등한 성능을 보였습니다.
이 성능은 VITON-HD 데이터셋을 이용해 학습하였을 때의 성능이고, 다른 데이터셋을 사용했을 때의 성능도 논문에 첨부되어 있으
니 참고하시길 바랍니다.
4. Limitations

StableVITON 은 다음과 같은 한계점이 있다고 합니다.
1. 가상 피팅을 적용할 인체 위에 다른 물체가 놓여있다면, Output 에서 그 물체가 사라집니다.
2. 가상 피팅을 적용할 인체의 악세서리를 보존하지 못합니다.
3. 변형이 되지 말아야 하는 부위 (아래 사진에서 눈 부위)가 미세하게 변형될 때도 있다고 합니다.

5. Opinion
이전에 발표된 VITON 모델을 hugging face 데모 버전 사용했을 때, 꽤 괜찮은 Output 결과를 얻었는데, 이 모델은 더 발전시켰다는 게 흥미로웠습니다. Stable Diffusion 의 Zero-Shot Learning 방식에서 착안한 Zero Cross-Attention Block으로 의류와 신체의 조화를 정교하게 구현하려 했으나, 새로운 문제가 발생했고, Attention Total Variation Loss라는 간단한 방식으로 해결한 점이 인상적이었습니다. 저 또한 기존 논문에서 아이디어를 얻어서 모델을 발전시킬 수 있으려면 앞으로 이러한 창의적 접근 방식의 논문을 많이 접해야겠다는 생각이 드네요 !
6. Optional
공개 코드도 있으니 StableVITON 모델이 궁금하다면 확인해보시길 바랍니다.
Github : https://github.com/rlawjdghek/StableVITON
GitHub - rlawjdghek/StableVITON: [CVPR2024] StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtua
[CVPR2024] StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On - rlawjdghek/StableVITON
github.com